首先看一下hash的常用命令
hset key field value
hsetnx key field value
hget key field
hexist key field
hdel key field [field...] //一次删除多个field
hlen key //key中field的数量
hstrlen key field //field对应value的string的长度
hincrby key field increment
hincrbyfloat key field increment
hmset key field value [field value]
hmget key field [field]
hkeys key //返回所有的field
hvals key //返回所有的value
hgetall key
hscan key corsur pattern count
如果我们用string类型存储一个用户对象数据,当对象中的属性频繁变化的时候会涉及到频繁的序列化和反序列化;如果我们用用户id+对象的属性作为一个key来存储,会造成用户id重复存储。此时hash可以很好的解决这个问题,用户id作为key,每一个属性作为一个field,这样就可以避免序列化和反序列化的消耗,快速修改每一个对象的属性。
ZIPLIST
hash对象的底层存储使用了ziplist(压缩列表)和hashtable,当hash的field和value都小于64字节并且hash的field个数小于512的时候使用ziplist存储,否则使用 hashtable存储,以上两个门限可在redis.conf进行配置。
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
ziplist是一个内存高效的双向链表,避免了真正链表的内存碎片,指针等等的空间浪费,可以以O(1)的时间在链表两端进行push和pop操作,ziplist的结构如下
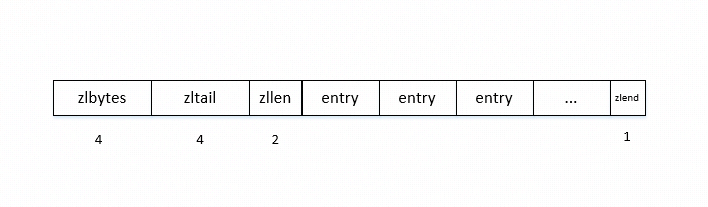
zlbytes表示整个ziplist的总字节数,zltail表示最后一个entry的offset,zllen整个ziplist中entry的个数,当entry的个数超过(2^16-2)时,设置zllen为(2^16-1),此时我们需要遍历ziplist来确定entry的个数。zlend表示ziplist的最后一个元素,固定编码成8字节的255。
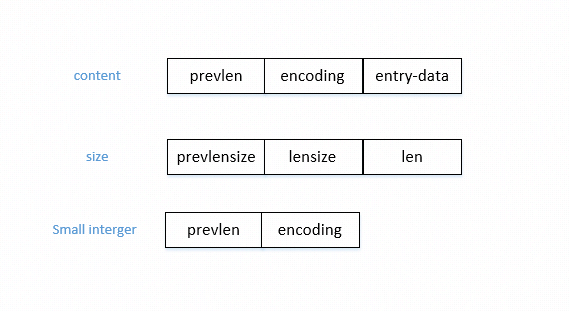
每一个field或者value被编码成一个entry顺序存放,每一个entry包含两部分元数据,一个是前一个entry的长度,这是为了从后往前遍历,因为每一个entry可能是变长的;第二个是当前entry的编码方式,可能是整型或者字符串,字符串的时候同样也包含了所存储字符串的长度。一个完整entry的存储结构如下
先看一下源码中entry的数据结构是如何定义的,这个并不是entry的数据结构组织形式,
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
上一个entry的长度小于254字节的时候,prevlen将占用一个字节大小来表示,也就是prevlensize;当prevlen超过254字节的时候,prevlensize将用5个字节表示,第一个字节是254,剩下的四个字节将表示上一个entry的长度。 根据存储的数据是int还是string,encoding区域是不同的编码方式。在string的情况下,第一个字节的前2个bit表示了不同长度的string,第3bit开始存储string的实际长度。在int的情况下,第一字节的前2bit固定存储1。以下表示了不同类型的encoding,从encoding的第一个字节我们可以了解entry存储的实际数据类型。
1. |00pppppp| - 1字节 长度小于63字节(6bit)的string,"pppppp"表示string的长度
2. |01pppppp|qqqqqqqq| - 2字节 长度小于16383字节(14bit)的string
3. |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5字节 长度大于16384字节的string,后面的4字节表示了string的长度,最大到2^32-1
4. |11000000| - 共3字节,表示一个2字节的int
5. |11010000| - 共5字节,表示一个4字节的int
6. |11100000| - 共9字节,表示一个8字节的int
7. |11110000| - 共4字节,表示一个3字节的int
8. |11111110| - 共2字节,表示一个1字节的int
9. |1111xxxx| - small integer,encoding中包含了data项
10. |11111111| - 特殊的ziplist的最后一项
第9种情况,由于xxxx的值在0001和1101之间,因为0000和1110与已有的数据冲突,那么xxxx就表示1-13,小数值从0开始,那么这13个值就表示0-12,需要用编码的值减1才是真正存储的值。 下面我们举一个ziplist的例子看一下
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
zlbytes zltail entries "2" "5" zlend
在ziplist中,所有的整型数据都是以小端字节序存放的,也就是低字节在内存低地址,这和我们平时的阅读习惯相反,我们习惯以大端字节序阅读,也就是低字节存放在内存高地址,因此,0x0f000000实际表示为0x0000000f,zltail和entries以此类推。可以看到,zlbytes表示15,整个ziplist有15字节。zltail为12,最后一个entry 0x02f6的offset为12。entry的个数是0x0002,有两个entry 0x00f3和0x02f6。第一个entry0x00f3,prevlen是00,因为我们是第一个entry,encoding是f3,符合上 述第9种情况,因此表示为2,同理,0x02f6中prevlen是2,上一个entry是2个字节,表示数据为5。 这个一个string类型的entry,
[02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64]
其中,prevlen是2,encoding是0x0b,符合第一个中情况,是一个string,string的长度为11,0x48656c6c6f20576f726c64为11字节,表示”Hello World”。
hash table
hash table是经典数据结构,在Java中也有重要应用。用数组存放每一个键值对,使用链表解决hash冲突。对redis hash的增删改操作实际就是对hash table的操作。
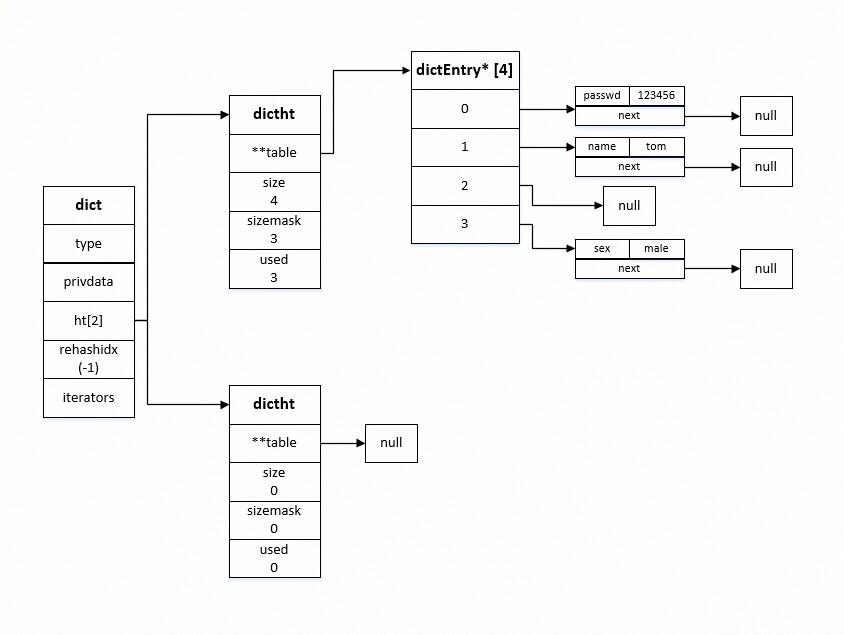
看下源码中是如何定义hash table数据结构的
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
/* hashtable的结构,每个dict有两个dictht,用来进行增量rehash */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
/* 每一个键值对存放的位置, next用来解决hash冲突 */
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
/* 自定义的操作key和value的方法 */
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); //hash函数
void *(*keyDup)(void *privdata, const void *key); //复制key
void *(*valDup)(void *privdata, const void *obj); //复制val
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //比较key的函数
void (*keyDestructor)(void *privdata, void *key); //销毁key
void (*valDestructor)(void *privdata, void *obj); //销毁val
} dictType;
hash函数
对hash的任何操作首先需要通过hash函数计算出hash值,进而计算在hash table中的索引位置。hash函数的设计优劣决定了hash冲突的大小。redis默认采用SipHash作为 hash计算方式。
uint64_t siphash(const uint8_t *in, const size_t inlen, const uint8_t *k) {
#ifndef UNALIGNED_LE_CPU
uint64_t hash;
uint8_t *out = (uint8_t*) &hash;
#endif
uint64_t v0 = 0x736f6d6570736575ULL;
uint64_t v1 = 0x646f72616e646f6dULL;
uint64_t v2 = 0x6c7967656e657261ULL;
uint64_t v3 = 0x7465646279746573ULL;
uint64_t k0 = U8TO64_LE(k);
uint64_t k1 = U8TO64_LE(k + 8);
uint64_t m;
const uint8_t *end = in + inlen - (inlen % sizeof(uint64_t));
const int left = inlen & 7;
uint64_t b = ((uint64_t)inlen) << 56;
v3 ^= k1;
v2 ^= k0;
v1 ^= k1;
v0 ^= k0;
for (; in != end; in += 8) {
m = U8TO64_LE(in);
v3 ^= m;
SIPROUND;
v0 ^= m;
}
switch (left) {
case 7: b |= ((uint64_t)in[6]) << 48; /* fall-thru */
case 6: b |= ((uint64_t)in[5]) << 40; /* fall-thru */
case 5: b |= ((uint64_t)in[4]) << 32; /* fall-thru */
case 4: b |= ((uint64_t)in[3]) << 24; /* fall-thru */
case 3: b |= ((uint64_t)in[2]) << 16; /* fall-thru */
case 2: b |= ((uint64_t)in[1]) << 8; /* fall-thru */
case 1: b |= ((uint64_t)in[0]); break;
case 0: break;
}
v3 ^= b;
SIPROUND;
v0 ^= b;
v2 ^= 0xff;
SIPROUND;
SIPROUND;
b = v0 ^ v1 ^ v2 ^ v3;
#ifndef UNALIGNED_LE_CPU
U64TO8_LE(out, b);
return hash;
#else
return b;
#endif
}
扩容&缩容&rehash
当hash表的大小不能满足需求的时候,就会有两个或者两个以上的key被分到hash表的同一个索引上,引发冲突。为了尽量避免冲突,需要对hash表进行扩容和收缩。那么当hash表的大小变化了之后随之而来的就是rehash操作。 扩容:在每一次对key计算hash的时候,都会判断hash表是否需要进行扩容。当hash表的元素个数大于表大小的时候,会扩容为元素个数的2倍;当redis在进行bgsave(RDB持久化)的时候尽量避免扩容(dict_can_resize),但是当元素个数是表大小5倍的时候,会强制进行扩容。
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table
* 如果redis正在进行rehash,是不会进行扩容操作的,因为rehash就代表了正在进行扩容。
* */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing
会将dictht赋值给ht[1]
渐进式rehash,分多次,持续进行,不影响服务器性能。每次增删改查都会执行单步rehash。rehash的时候ht[0]和ht[1]都会有数据
dict中有rehashidx,-1表示不进行rehash,非-1就表示要开始进行rehash了,每次单步rehash就会给rehashidx自增1
rehash完成时,rehasidx=-1
*/
d->ht[1] = n;
d->rehashidx = 0; /*扩容后开始rehash,ht[0]往ht[1]上搬运,直到完成,将ht[0] = ht[1]*/
return DICT_OK;
}
缩容:因为删除导致hash表元素原来越少的时候,redis会对hash进行缩容来减小空间,当使用的表大小不到整个表的10%的时候,会将表空间缩小到所使用元素的大小。
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
/* Resize the table to the minimal size that contains all the elements,
* but with the invariant of a USED/BUCKETS ratio near to <= 1 */
int dictResize(dict *d)
{
unsigned long minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal);
}
rehash:dictRehash就是将第一个table的元素复制到第二个table上,删除第一个table的元素。n表示要在第一个table上进行rehash的元素的个数(不包含链表中元素),为了防止空元素过多,导致方法无限循环而阻塞,设置了最大空元素的访问个数empty_visit。将第一个的table的元素(包含链表)rehash到第二个table上。在n次 rehash完成之后,如果table1整个为空,则将table2重新作为table1,结束rehash。
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
/**
* 在通常的查找或者更新操作中都会执行渐进式rehash。每次只rehash一个元素。
* 迭代就是ht[0]开始,一个元素一个元素的遍历,再到ht[1]一个元素一个元素的遍历。
* 前提是hash表没有安全的迭代,在rehash的过程中如果有安全的迭代的话,rehash会造成重复迭代元素。
*/
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
/**
* 迭代记录了当前元素以及下一个元素,当前元素是null,会去table中取,取的过程会判断是否是安全的迭代,是则iterators++
* 拿到当前元素会返回,同时记录next元素。下次迭代会直接将next元素作为当前元素返回。
*/
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
if (iter->index == -1 && iter->table == 0) {
if (iter->safe)
iter->d->iterators++;
else
iter->fingerprint = dictFingerprint(iter->d);
}
iter->index++;
if (iter->index >= (long) ht->size) {
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
} else {
break;
}
}
iter->entry = ht->table[iter->index];
} else {
iter->entry = iter->nextEntry;
}
if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
return NULL;
}
dictScan实现
dictScan方法是hscan命令的底层实现,dictNext在可以是安全的迭代,而安全的迭代是不允许rehash的发生。但是hscan命令是client主动发起的,不能阻止rehash的发生。通过初始化cursor=0,返回迭代元素及新的cursor,下一次通过返回的cursor继续迭代。如果没有rehash,只有一个table的时候,dictScan很容易实现,但是rehash的时候将会出现两个table,如果dictScan和rehash同时发生,那么如何保证在迭代的过程中不重复迭代,也不漏掉元素,dictScan设计了一个很精妙的迭代顺序。
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
dictScanBucketFunction* bucketfn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de, *next;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
/* Having a safe iterator means no rehashing can happen, see _dictRehashStep.
* This is needed in case the scan callback tries to do dictFind or alike. */
d->iterators++;
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
} else {
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t1->table[v & m1]);
de = t1->table[v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Increment the reverse cursor not covered by the smaller mask.*/
v |= ~m1;
v = rev(v);
v++;
v = rev(v);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
/* undo the ++ at the top */
d->iterators--;
return v;
}
首先会给iterators自增1,最后方法执行完将iterators减1,保证在一次dictScan的实现过程中不进行增量式rehash。如果dict没有进行rehash,扫描cursor对应的元素及链表的元素并全部返回,再计算要返回的cursor。如果dict正在进行rehash,会先迭代小的table,再迭代大的table。下面主要看一下这个迭代算法是如何返回下一个要迭代的cursor的。 下一个要迭代的cursor的计算方式正好和我们平时的计算方式相反,高位加1向地位进位。根据dictScan我们写一个简单的测试函数
#include <stdio.h>
#include <stdlib.h>
#include<math.h>
unsigned long size;
unsigned long v;
unsigned long rev(unsigned long v) {
unsigned long s = 8 * sizeof(v); // bit size; must be power of 2
unsigned long mask = ~0;
while ((s >>= 1) > 0) {
mask ^= (mask << s);
v = ((v >> s) & mask) | ((v << s) & ~mask);
}
return v;
}
void init(void) {
size = 8; /* Initial table size. */
v = 0; /* Initial cursor position. */
printf("--- size: %d\n", (int)size);
}
void print_bin(unsigned long v) {
unsigned long bit = 1<<15;
while(bit) {
if (bit<<1 <= size) {
printf("%s", (v&bit) ? "1" : "0");
}
bit >>= 1;
}
}
int main(void) {
init();
print_bin(v);
printf(" --> ");
unsigned long mask = size-1;
do {
v |= ~mask;
v = rev(v);
v++;
v = rev(v);
print_bin(v);
printf(" --> ");
} while(v);
printf("\n");
return 0;
}
size表示dict中table的长度,print_bin打印v的低n位,n等于log2(size),我们分别用size=8和16进行测试,输出结果如下,
size:8 000 --> 100 --> 010 --> 110 --> 001 --> 101 --> 011 --> 111 --> 000
size:16 0000 --> 1000 --> 0100 --> 1100 --> 0010 --> 1010 --> 0110 --> 1110 --> 0001 --> 1001 --> 0101 --> 1101 --> 0011 --> 1011 --> 0111 --> 1111 --> 0000
table的长度为8的时候,第i个cursor(0<=i<=7)扩展到长度为16的table的时候,对应第2i和2i+1个。 首先时table扩展的情况,假设当前table的长度是8,在迭代完010的时候,table的长度扩展到了16,下一个110在长度为16的table中变成0110,那么就从0110开始迭代。此时,在长度为8的情况下,已经迭代过000,100,010,这三个节点扩展到长度为16的table中的时候,对应,0000,1000,0100,1100,0010,1010,而这6个节点刚好在0110这个节点之前,此时,按照长度为16的table迭代下去,既不会重复迭代,也不会漏掉节点。
然后是table缩小的情况,假设table的长度是16,在迭代完0100这个节点后,将要迭代1100这个节点,此时table发生了收缩,长度变为8,1100这个节点在长度为8的table中是100,在长度为16的时候,已经迭代过0000,1000,0100,那么在长度为8的table中将从100开始迭代,会重复迭代0100这个元素。但是假设在将迭代0010这个元素的时候发生了收缩,就不会重复迭代元素。因此,也只是在某些情况下发生重复迭代。 所以,这个迭代的顺序保证既不会漏掉元素,也能最大程度的减少重复迭代。 如果我们按照正常的顺序迭代,在长度为8和16的情况下,cursor的变化过程如下
size:8 000 --> 001 --> 010 --> 011 --> 100 --> 101 --> 110 --> 111 --> 000
size:16 0000 --> 0001 --> 0010 --> 0011 --> 0100 --> 0101 --> 0110 --> 0111 --> 1000 --> 1001 --> 1010 --> 1011 --> 1100 --> 1101 --> 1110 --> 1111 --> 0000
假设在长度为8的时候,我们迭代完010,将要迭代011的时候table的长度扩展到16,011在长度为16的table中为0011,在长度为8的情况下,已经迭代过000,001,010,这三个节点扩展到长度为16的table中的时候,对应,0000,1000,0001,1001,0010,1010,在长度为16的情况下我们从0011开始迭代,这样的话之前迭代过的1000,1001,1010就会重复迭代。
hset的实现
首先看下在t_hash.c中定义的hsetCommand方法
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
if ((c->argc % 2) == 1) {
addReplyError(c,"wrong number of arguments for HMSET");
return;
}
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
hashTypeTryConversion(o,c->argv,2,c->argc-1);
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
char *cmdname = c->argv[0]->ptr;
if (cmdname[1] == 's' || cmdname[1] == 'S') {
/* HSET */
addReplyLongLong(c, created);
} else {
/* HMSET */
addReply(c, shared.ok);
}
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
server.dirty++;
}
hset命令的底层实现,首先会查找field是否存在,存在则直接返回响应对象,否则创建新对象。查看对象的长度是否需要将ziplist转换为hashtable。然后判断是ziplist还是hashtable分别进行设置field和value的操作。然后发出键更改的信号,再通知键空间事件。 如果是ziplist,设置field和value的操作如下
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
/* Delete value */
zl = ziplistDelete(zl, &vptr);
/* Insert new value */
zl = ziplistInsert(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* Check if the ziplist needs to be converted to a hash table */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
首先计算ziplist第一个entry的指针,然后找出是否设置过field,如果设置过field,先将value对应的entry删除,再插入新的value。如果没有设置value,则将field和value都插入ziplist中。最后需要判断ziplist中entry的长度,符合条件的话需要将ziplist转换为hashtable。