redis当中有两类事件,一个是时间事件,一个是文件事件。
- 时间事件(time event),redis server中的一些定时操作,比如serverCron方法,需要在给定的时间执行操 作。
- 文件事件(file event),主要用来处理网络IO,比如一个client的连接到来,将数据 从缓冲区读入(read),将数据写入输出缓冲区(write),就会产生文件事件,进而调用与套接字绑定的事件处理器对事件进行处理。
文件事件

IO多路复用程序对所连接的套接字进行监听,返回产生了事件的套接字给分派器。 文件事件实际上是对套接字操作的抽象,当一个套接字产生连接(accpet),准备读(read),准备写(write),关闭连接(close)的时候就会产生一个文件事件。一个server可以同时被多个client连接,所以,套接字的事件可能并发的产生,但是却不会并发的执行,IO多路复用程序会将产生事件的套接字的放到一个队列中(下文中描述的aeEventLoop中的fired就绪事件表),事件处理器会以有序、同步、单个的方式处理每一个事件,这就是常说的redis单线程执行,即使多客户端并发,在server端命令也是单线程顺序的执行。内存操作加IO多路复用机制使 我们的单线程操作也可以很快。
时间事件
redis的时间事件可以分为两类
- 定时事件,在指定时间之后执行一次
- 周期性时间,每隔指定时间就执行一次
时间事件的数据结构定义如下
/* Time event structure */
typedef struct aeTimeEvent {
long long id; /* time event identifier. 标识时间事件的唯一id*/
long when_sec; /* seconds 时间事件到达的秒 */
long when_ms; /* milliseconds 时间事件到达的毫秒*/
aeTimeProc *timeProc; /*回调函数*/
aeEventFinalizerProc *finalizerProc;
void *clientData;
struct aeTimeEvent *prev; /*前驱节点 时间事件组成一个链表*/
struct aeTimeEvent *next;
int refcount; /* refcount to prevent timer events from being
* freed in recursive time event calls. */
} aeTimeEvent;
redis会将所有的时间事件按创建顺序放在一个链表中,每次遍历这个链表找到发生时间已经到达的事件,执行回调函数。执行完成之后,对于定时事件,会对唯一id做标识,下次遍历到的时候就会删除事件并释放空间;对于周期性事件,根据执行频率更新当前事件的发生时间,以待下次触发。
事件的初始化过程

我们看下初始化阶段中的各个步骤
配置初始化。 配置初始化阶段redis首先初始化所需要的基本配置,比如tcp socket相关参数,aof持久化相关参数,加载commandTable,commandTable硬编码了redis所有命令的参数及入口函数地址。加载redis的标准配置,再从配置文件reids.conf中载入配置来覆盖原有标准配置。还包括用户权限相关Acl初始化。初始化阶段还会创建redis的共享对象,redis当中存储的所有值都以redisObject的形式出现,共享对象是为了节约内存,共享对象包括0-9999的整数以及redis通用的一些字符串,有ERR,OK,PONG,syntax error 这类的。其他的字符串redis并没有创建共享对象。
创建事件循环。 初始化事件循环的主要数据结构aeEventLoop,当中包括时间事件和文件事件,对于文件事件,依照不同的操作系统选择不同的多路复用方法,例如epoll,kqueue等,然后初始化epoll获取句柄,为之后的 IO多路复用做准备。
监听文件描述符。 初始化文件描述符并监听ip和端口,这是tcp的监听方式,同时也会监听unix domain socket,这是一种同一主机上的进程间通信方式,效率高于tcp。
注册时间事件回调。 在aeEventLoop的时间事件链表中加入时间事件,注册时间事件回调函数serverCron,这个方法增量式处理一些后台的操作,比如客户端超时,删除一些过期key等等。通过事件循环机制周期性的调用serverCron方法,事件循环机制是在redis的主线程当中执行的,因此,周期性操作也是在主线程当中执行。
注册文件事件回调。 对已经创建的连接实际上就是文件描述符创建一个文件事件,就是将文件描述符加到epoll句柄中,通过IO多路复用监听它的可读或者可写动作,并注册事件的回调函数。回调函数包括从缓冲区读取命令,解析执行,将结果写到输出缓冲区。当然,整个文件事件的回调也是包含在事件循环当中的,监听也包括Tcp连接的监听和unix domain socket的监听。
初始化后台线程。 除了redis的主线程之外,redis会开启后台多个线程来处理一些比较耗时的操作,目前有三种,删除文件,推迟的aof持久化,释放资源。后台多线程开启的目的是为了避免这些操作阻塞主线程。每个线程会保存一个队列,将需要执行的任务放到这个队列中依次执行。另一个操作就是如果配置文件开启了多线程IO,则创建并初始化多线程。
启动事件循环。 最后一步就是启动事件循环,在循环当中,如果当前时间大于等于时间事件的发生时刻就执行时间事件的回调,有IO事件发生时就执行文件事件的回调。
那么事件循环具体是如何执行的呢?
事件循环的执行过程(单线程 多线程)
首先我们看下事件管理器aeEventLoop是如何管理时间事件和文件事件的
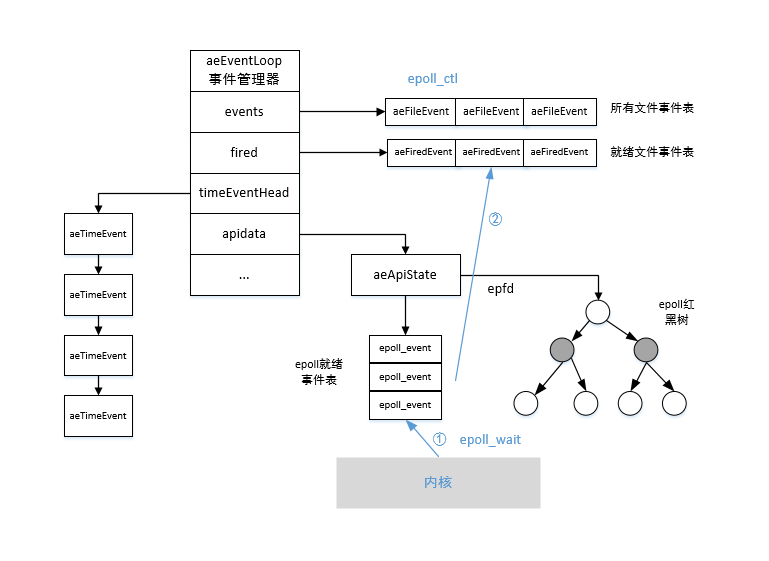
可以看到aeEventLoop结构主要包含三部分,时间事件链表,文件事件数组,以及多路复用的结构。 因为redis中同时存在时间事件aeTimeEvent和文件事件aeFileEvent,所以redis必须对这两个事件进行调度,决定何时执行时间事件,何时执行文件事件。 事件循环的入口是aeMain方法,aeMain方法通过while循环来持续处理文件事件和时间事件
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
aeProcessEvents(eventLoop, AE_ALL_EVENTS|
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
为了直观,我们将事件处理函数以伪代码的形式呈现
int aeProcessEvents(aeEventLoop *eventLoop, int flags){
/* 查找时间事件链表中最近要发生事件的时间 */
shortest = aeSearchNearestTimer(eventLoop);
/* 当前时刻距即将发生的时间事件还有多少ms */
long long ms = (shortest->when_sec - now_sec)*1000 + shortest->when_ms - now_ms;
/* 如果已经过了发生的时间 将tvp置位0 */
if (ms > 0) {
tvp->tv_sec = ms/1000;
tvp->tv_usec = (ms % 1000)*1000;
} else {
tvp->tv_sec = 0;
tvp->tv_usec = 0;
}
/* epoll前要执行的方法,包括多线程IO。*/
if (eventLoop->beforesleep != NULL && flags & AE_CALL_BEFORE_SLEEP){
eventLoop->beforesleep(eventLoop);
}
/* 实行IO多路复用,阻塞等待IO事件的发生,将所有发生最大阻塞时间为tvp */
numevents = aeApiPoll(eventLoop, tvp);
/* */
if (eventLoop->aftersleep != NULL && flags & AE_CALL_AFTER_SLEEP){
eventLoop->aftersleep(eventLoop);
}
/* 执行文件事件回调,处理已产生的文件事件 */
processFileEvents();
/* 执行时间事件回调,处理已产生的时间事件 */
processTimeEvents();
}
首先遍历时间事件的链表,找出最近要发生的时间事件,将这个时间与当前时间之差作为epoll的超时等待时间,这个时间之内如果有IO事件的发生则执行相应的回调,否则超时退出之后执行时间事件的回调。在epoll之前如果有beforeSleep方法,则先执行beforeSleep方法,beforeSleep方法中包含了IO操作,也就是将client的query数据从缓冲区读出,或者将响应数据写入输出缓冲区,同时在开启多线程IO的情况下beforeSleep方法会阻塞直到所有IO线程完成读写操作(读操作之后不解析执行具体的命令,否则会发生竞争)。aeApiPoll就是redis真正实现IO多路复用的地方,redis根据当前的操作系统选择不同的多路复用方法,比如select或者epoll。在使用epoll的情况下,该方法直接返回发生了读或者写的文件描述符,根据这些文件描述符及其对应的读写事件,执行相应的回调方法,这就完成了IO事件的读或者写。在处理完文件事件之后开始处理时间事件。时间事件的处理方法是遍历时间事件链表,对于发生时间已经到达的时间事件立即执行时间回调,回调方法会告诉你当前时间事件是否是周期性执行事件,是的话更细下一次执行的时间,否则删除此时间事件。
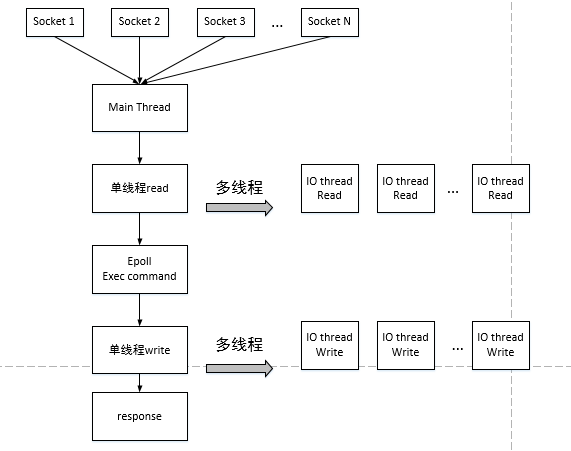
在6.0版本之前redis一直是单线程的,也就是说由主线程来处理输入缓冲区,多路复用获得发生IO事件的文件描述符,解析输入并执行命令,最后输出,整个过程都是单线程完成的。redis的瓶颈在于内存和网络IO,为了进一步提高redis的性能,在redis6.0版本网络IO可以配置为多线程处理,也就是由多线程来将数据从输入缓冲读出,但并不执行,最终所有的命令还是由主线程来完成,这样避免了竞争同时提高了性能。我们看下redis单线程和多线程处理数据的模型。
linux中的IO模型
网络IO的本质是对socket的读取,Linux中socket被抽象为文件,IO实际上就是对文件的读取和写入,当一个read操作发生时,它会经历两个阶段, (1)等待数据准备,socket层面就是等待数据分组的到达,并将数据复制到内核缓冲区。 (2)将数据由内核缓冲区拷贝到用户进程缓冲区。
下面分析下Linux中几种IO模型
同步阻塞IO(blocking IO)
用户进程发起了一个系统调用比如read,进程就立即被阻塞了,不消耗CPU,不干任何别的事,等待响应数据的到来。
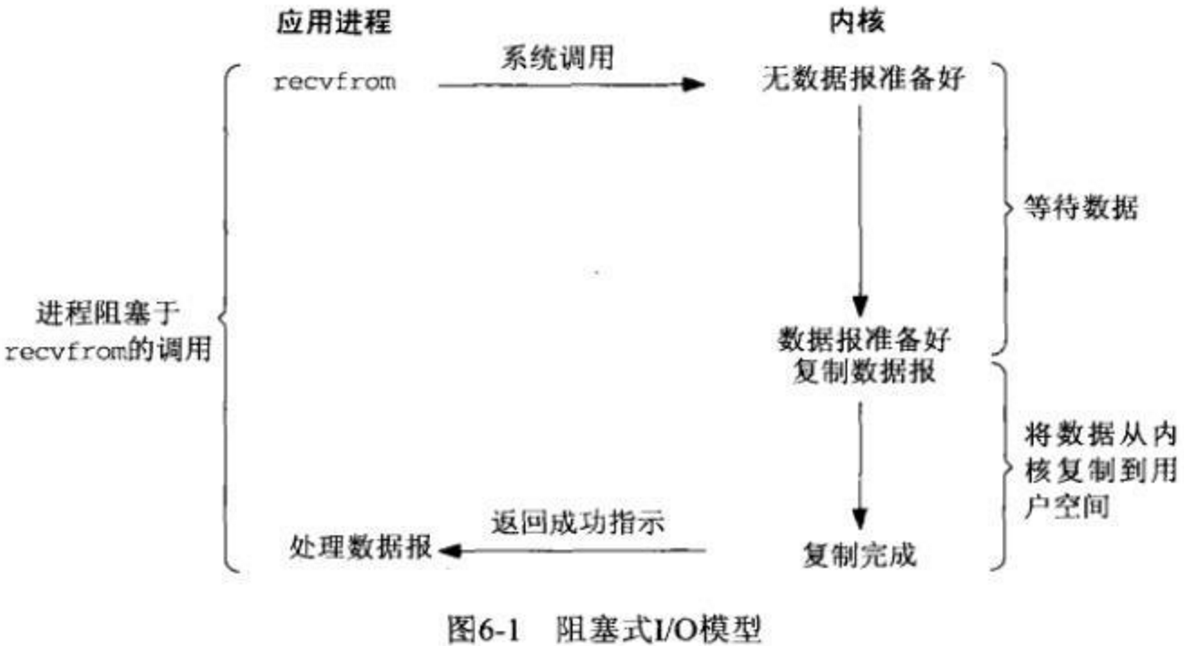
优点:对开发者友好,简单。 缺点:不能很好的利用进程资源,使IO的性能降低。
同步非阻塞IO(nonblockinhg IO)
用户进程发起了一个系统调用比如read,进程立即返回一个error,这个时候进程可以干点别的事,然后再立即发起一个和刚才一样的系统调用,如果数据准备好了则立即将数据拷贝到用户进程;否则还是返回一个error。进程就这样以轮询的方式不断的发起read操作,直到数据准备好返回为止。
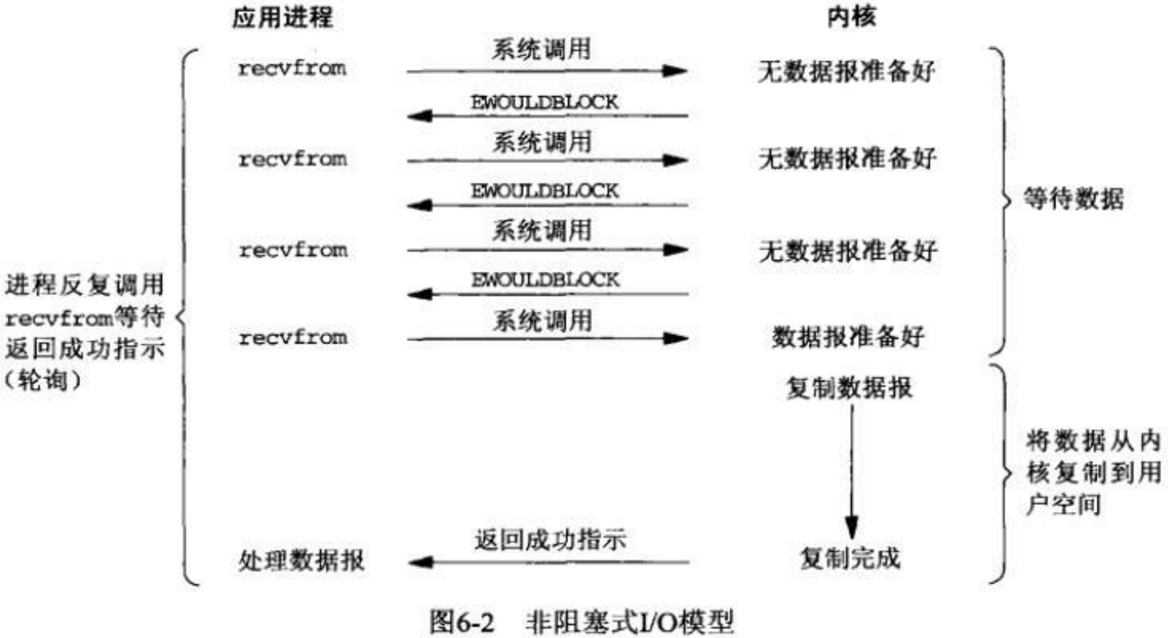
优点:不用一直阻塞进程,在多次轮询期间进程可以有别的操作。 缺点:数据准备好的时刻可能发生在两次轮询期间,这样会增大响应时间,降低系统吞吐量。
多路复用IO (multiplexing IO)
IO多路复用的核心是使用了系统级的调用,select,epoll等。它可以等待多个socket,实现对多个IO端口进行监听,当有任何一个可读或者可写事件发生的时候,epoll就会返回这个对应的文件描述符,然后再对这个文件描述符执行read或者write操作。当然,执行epoll方法等待文件描述符的返回过程是阻塞的,那如何知道哪一个文件描述符发生了可读或可写事件呢?这个监视的事情是交由内核处理的。与阻塞IO不同的是多路复用IO是可以一次等待多个socket,当有数据到来的时候会自动返回对应的文件描述符。
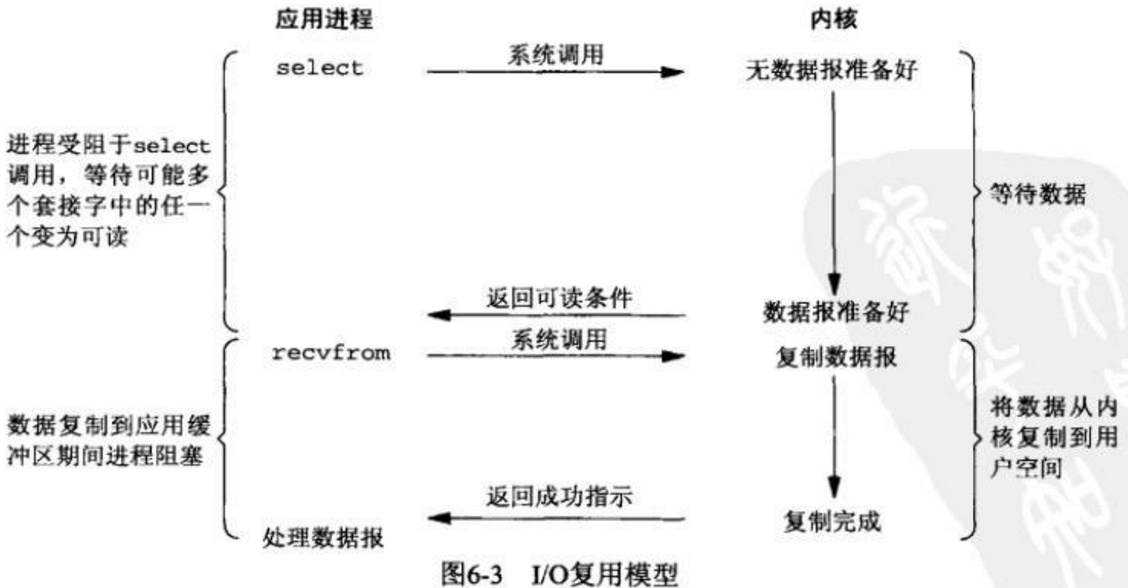
epoll与select的区别。epoll比select更加高级,select是通过对所有监听的文件描述符进行遍历得到活跃的socket,当文件描述符集合很大并且活跃数很少的时候select的性能会严重降低,并且select所监听的文件描述符数量是有限的,限制为单个进所能打开的最大文件数的,通过ulimit -n查看。epoll所监听的文件描述符的数量可以认为是无限的,并且对文件描述符设置了callback,当文件描述符活跃的时候会主动调用callback,这样就可以很快的获得活跃的文件描述符,避免了select的遍历带来的性能损耗。
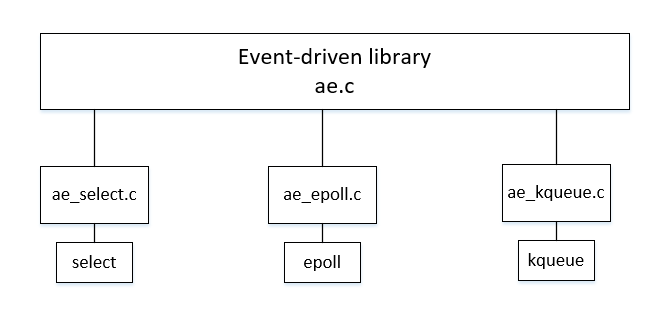
redis中如何多路复用
redis封装了多个多路复用模块,select,epoll,kqueue。每个模块为上层提供了相同的接口,redis根据不同的操作系统和性能选择最适合的多路复用模块。