常用命令
set key value [ex] [px] [nx|xx]
setnx key value
setex key second value
get key
getset key value
strlen key
append key value
getrange key start end
setrange key offset value
incr/incrby/incrbyfloat key
decr/decrby key
mset key value [key value]
msetnx key value [key value]
mget key key
关于以上命令,有几点说明,
- set命令最后的nx参数,只在key不存在的时候设置,与setnx命令是同样的作用。xx参数,只在key存在的时候设置。setex与set命令一样,只不过可以同时设置失效时间。 setnx和setex在之后可能会被淘汰。
- getset命令,返回旧值,设置新值
- strlen返回字符串长度。如果存入的是数字的话,则将数字转为字符串后计算长度。
- getrange/setrange操作数字的时候,会将数字转为字符串,再按照字符串来操作
- incr/decr只对数字操作有效,字符串操作报错。
- msetnx,仅当所有key都不存在的时候才为所有key设置value,只要有一个key存在则拒绝为所有key执行设置操作。msetnx是一个原子操作,要么全部设置,要么全部不设置。
sds数据结构分析
首先第一个问题,redis的string类型为什么不使用C的原生字符串,有两个原因,一个是原生的C字符串是二进制不安全的,它以’\0’结尾,所以他不能用来存储任意的二进制数据;对于原生的C字符串无法以O(1)的速度拿到字符串长度。所以redis的string类型没有使用原生的C字符串,而使用了改进的SDS(Simple Dynamic String),简单动态字符串。sds由两部分组成,header和真正存储数据的字符数组部分,同时,sds又定义为 *char 类型,
typedef char *sds;
sds中的字符数组以’\0’结尾,使sds又兼容了原生C字符串的用法。我们看下sds中对header的定义
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
首先我们可以看到sds的header结构体声明时使用了 attribute ((packed)) 。这实际上是让C的struct不进行字节对齐,使用紧凑的方式排列,这样可以直接通过内存来访问变量。 通常情况下,C在建立结构体的时候会自动进行字节对齐,所以实际占用内存比变量的字节数多一些,来看一个例子
#include <stdio.h>
#include <iostream>
using namespace std;
struct test1 {
char c;
int i;
};
struct __attribute__ ((__packed__)) test2 {
char c;
int i;
};
int main()
{
cout << "size of test1:" << sizeof(struct test1) << endl;
cout << "size of test2:" << sizeof(struct test2) << endl;
}
输出如下
size of test1:8
size of test2:5
test1结构体没有用packed声明,所以使用4字节对齐的方式,即char变量也占用4个字节,加上int的4字节,一共8字节。test2使用了packed进行了声明,不进行内存字节对齐,所以占用内存就是变量所占用的5个字节。
header主要由四部分组成,
- len,string的实际长度
- alloc,为字符数组分配的长度,也即就是数组容量,多分配容量可以保证在append的时候不再分配内存。
- flags,用一个字节的前3bit表示header的类型,header的类型有5中,根据不同的string长度选择不同的header类型。
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
当所存储的string的长度在[2^5-1, 2^8)时,选择SDS_TYPE_8;当长度在[2^8-1, 2^16-1)时选择SDS_TYPE_16;当长度在[2^16-1, 2^32-1)时选择SDS_TYPE_32;当长度在[2^32-1, )时选择SDS_TYPE_64。可以看到redis无处不在的节约内存,不同的string长度选择不同的字节存储。
下面图示一下sds的结构
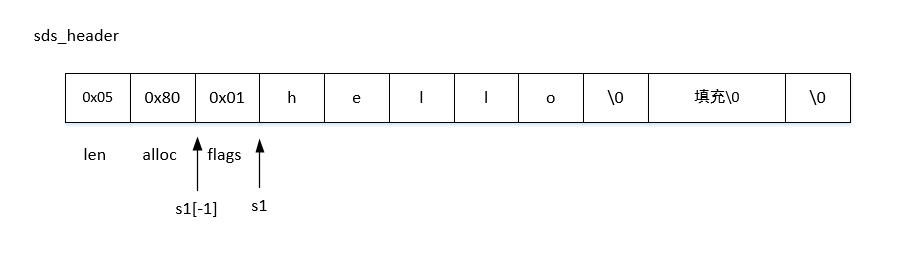
初始化sds的时候len与alloc是相等的,在可能的一些加长操作比如append或者setrange时会尝试先对sds中的字符数组进行分配空间扩容。
sds操作实现
首先看一下为sds分配空间的操作
/* Enlarge the free space at the end of the sds string so that the caller
* is sure that after calling this function can overwrite up to addlen
* bytes after the end of the string, plus one more byte for nul term.
*
* Note: this does not change the *length* of the sds string as returned
* by sdslen(), but only the free buffer space we have. */
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
sdsMakeRoomFor用来对sds进行扩容操作,也就是只改变alloc,不改变len,下面分析下主要执行步骤
- 如果sds剩余空间比要分配的空间大,则不执行分配操作,直接返回。
- 如果分配后的sds的len小于1M,则分配空间大小是len的2倍。
- 有可能扩容后sds的header的type会变化,需要计算新的sds的header type。
- 计算新的sds的header及字符数组的位置,为sds设置新的alloc
一些命令的实现
首先我们看一下set命令的实现,
/* SET key value [NX] [XX] [KEEPTTL] [EX <seconds>] [PX <milliseconds>] */
void setCommand(client *c) {
int j;
robj *expire = NULL;
int unit = UNIT_SECONDS;
int flags = OBJ_SET_NO_FLAGS;
for (j = 3; j < c->argc; j++) {
char *a = c->argv[j]->ptr;
robj *next = (j == c->argc-1) ? NULL : c->argv[j+1];
if ((a[0] == 'n' || a[0] == 'N') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' &&
!(flags & OBJ_SET_XX))
{
flags |= OBJ_SET_NX;
} else if ((a[0] == 'x' || a[0] == 'X') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' &&
!(flags & OBJ_SET_NX))
{
flags |= OBJ_SET_XX;
} else if (!strcasecmp(c->argv[j]->ptr,"KEEPTTL") &&
!(flags & OBJ_SET_EX) && !(flags & OBJ_SET_PX))
{
flags |= OBJ_SET_KEEPTTL;
} else if ((a[0] == 'e' || a[0] == 'E') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' &&
!(flags & OBJ_SET_KEEPTTL) &&
!(flags & OBJ_SET_PX) && next)
{
flags |= OBJ_SET_EX;
unit = UNIT_SECONDS;
expire = next;
j++;
} else if ((a[0] == 'p' || a[0] == 'P') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' &&
!(flags & OBJ_SET_KEEPTTL) &&
!(flags & OBJ_SET_EX) && next)
{
flags |= OBJ_SET_PX;
unit = UNIT_MILLISECONDS;
expire = next;
j++;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
c->argv[2] = tryObjectEncoding(c->argv[2]);
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}
- 解析命令中的nx,xx,ex,px参数,设置标志位flags
- 尝试对string类型进行重新编码程long或者embstr,以节省空间。此步骤的详细过程下面分析。
- 对于set的key和value执行新增或者复写操作。redis的一个database中的所有key-value是存储在一个dict上面的,对于一个value(无论是哪种类型,string或者hash),实际上都以redisObject的形式存在,redisObject当中包含了value对象的编码方式和实际数据存储的地址。
为了节省空间,redis会对string类型进行重编码,具体步骤如下
- 如果不是string类型则不进行重编码
- 对于string类型,如果不是RAW或者EMBSTR的编码方式,则不进行重编码
- 对于redis的共享对象不进行重编码。共享对象存在于整个redis空间中,并且随时可能被释放,所以不进行操作。
- 如果stirng类型存储的是数字并且小于long表示的最大整数,则将对象的编码方式由OBJ_ENCODING_RAW 转为 OBJ_ENCODING_INT,redisObject当中的ptr指针直接指向转换后的long型数据。
- 如果字符串的长度小于44,则将编码方式转为OBJ_ENCODING_EMBSTR,这是一种对内存更高效的存储方式,将redisObject和sds存储在连续的内存块中,从而减小内存碎片。
- 如果通过这一系列的操作string的编码方式没有转换,则判断sds当中剩余空间是否过大,大则释放多余空间。
sds和string
- string在redis内部实际有三种编码方式,OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_INT,前两种是用sds存储,最后一种直接将数据存储为了long型。
- 通常incr/decr只对数字有效,getrange/setrange只对真正的string有效。那当对string执行incr时,会首先将存储的string转为long,只有转换成功才执行操作。当对string型的数字执行getrange操作时,会先将long型数据转换为字符串再执行getrange操作。
所以,通常的string类型存储在sds当中,也就是在字符数组中,通过len属性可以快速读取长度;可以对字符数组进行切片读取或者部分设置的操作;通过不同的编码方式节省string的存储空间;支持对字符串和long的编码转换以适应不同的操作。
参考文章
- https://blog.csdn.net/weixin_39533180/article/details/76207099
- http://zhangtielei.com/posts/blog-redis-sds.html
- http://zhangtielei.com/posts/blog-redis-robj.html